Korrelationen
Korrelation ist ein Maß für den statistischen Zusammenhang zwischen zwei Datensätzen. Unabhängige Variablen sind daher stets unkorreliert. Korrelation impliziert daher auch stochastische Abhängigkeit. Bei der Berechnung einer Korrelation wird die lineare Abhängigkeit zwischen zwei Variablen quantifiziert.
Korrelationen werden i.A. der deskriptiven Statistik zugeordnet. Durch eine Reihe von Verfahren, wie z.B. partielle Korrelation, multiple Korrelation oder Faktorenanalyse, kann die einfache Korrelation zweier Variablen auf Beziehungen zwischen zwei Variablen unter Berücksichtigung des Einflusses weiterer Variablen werden. Korrelationen sind ein unverzichtbares Werkzeug für viele Forschungsgebiete.
Kausalität
Eine relevante (statistisch signifikante) Korrelation liefert keinen Beleg für die Kausalität. Vor allem in der Medizin und Psychologie suchen Forscher nach Kriterien für Kausalität. Es existieren mehrere Ansätze zur Erklärung der Ursächlichkeit einer Korrelation (siehe z.B. die 9 Bradford-Hill-Kriterien).
Linearität
Ein Korrelationskoeffizient zeigt die Stärke eines linearen Zusammenhangs zwischen zwei Variablen. Aber der Wert von \(r\) charakterisiert nicht die genaue Art des Zusammenhangs oder das Aussehen des Punktdiagramms beider Variablen5.
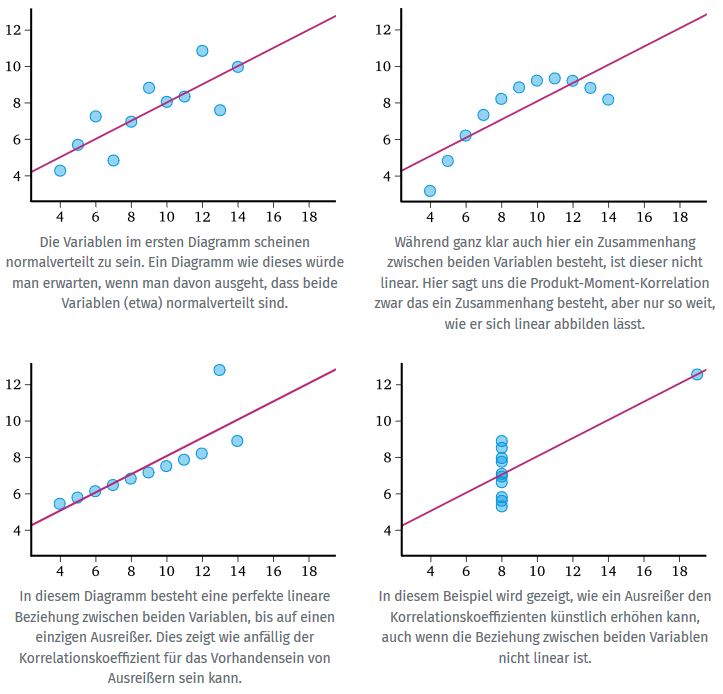
Abbildung 1: Korrelation und Linearität
Korrelationskoeffizienten
Neben dem Pearson-Produkt-Moment-Korrelationskoeffizienten \(r\) existieren noch etliche weitere Korrelationskoeffizienten und Zusammenhangsmaße. Die meisten hiervon sind Sonderfälle der Pearson-Produkt-Moment-Korrelation. Nachfolgende Tabelle zeigt, wann welcher Koeffizient berechnet werden soll. Die Verwendung unterschiedlicher Korrelationsberechnungen ist i.A. abhängig vom Skalenniveau der beteiligten Variablen.
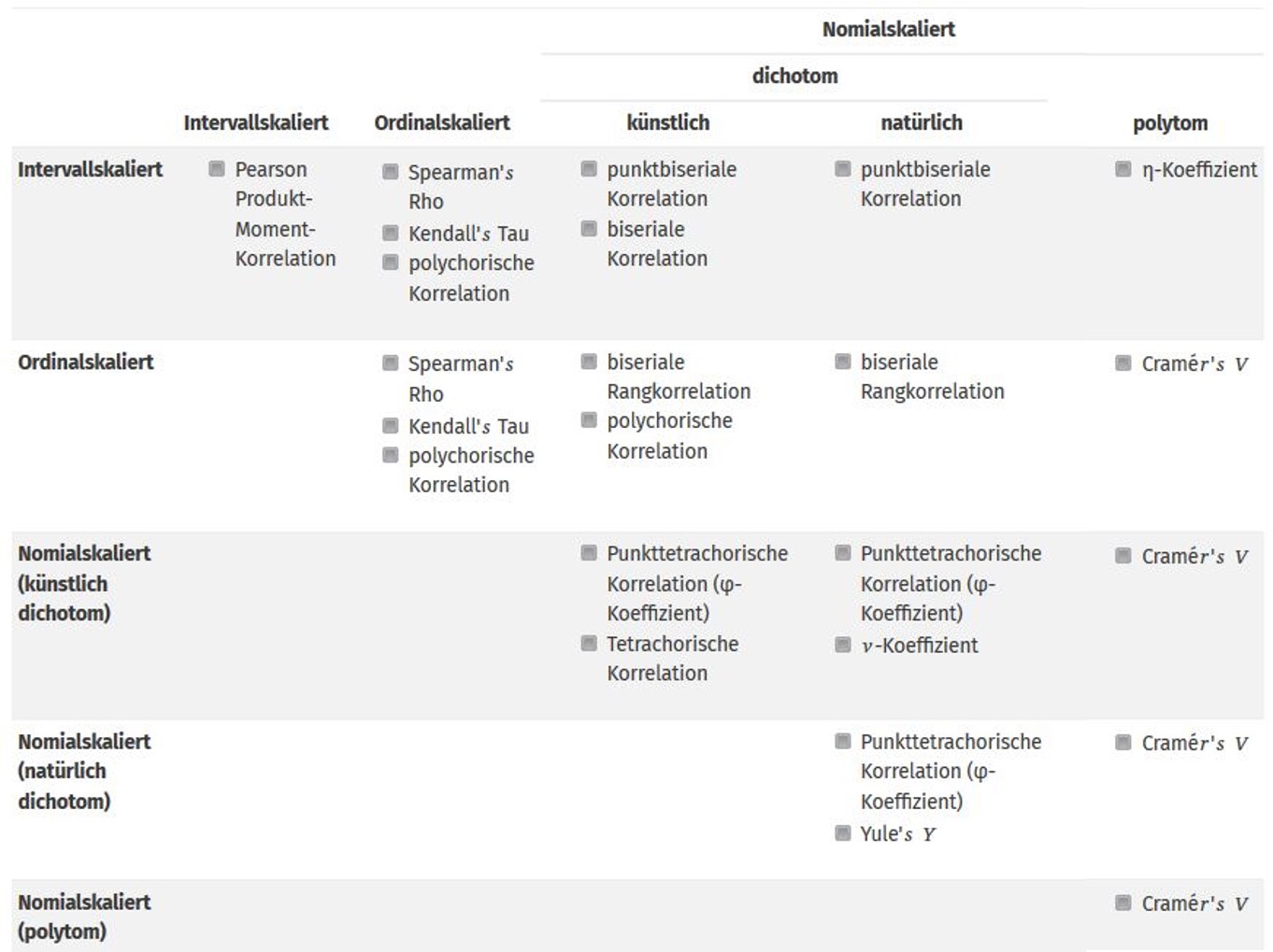
Abbildung 2: verschiedene Korrelationskoeffizienten
Weiter Infos zu den einzelnen Korrelationskoeffizienten sind der Literatur zu entnehmen. Eine übersichtliche Darstellung findet man auch auf der Website von MatheGuru.
Herleitung
Bereits bei der deskriptiven Statistik haben wir mit dem Maß der Varianz (\(s^2\)) einen Kennwert definiert, der die Schwankungen bezüglich des entsprechenden Mittelwertes beschreibt. Per Definition ist die Varianz die durchschnittliche Summe der quadrierten Abweichungen zum Mittelwert, also:
\[\begin{equation} s^2 = \frac{\sum_{i=1}^{N} (x_i - \bar{x})^2}{N-1} \tag{5} \end{equation}\]Betrachtet man zwei (normalverteilte) intervallskalierte Variablen \(x\) und \(y\), dann lässt sich diese Idee auch als ein Kennwert der gemeinsamen Variablität der beiden Variablen definieren:
\[\begin{equation} cov(x,y) = \frac{\sum_{i=1}^{N} (x_i - \bar{x}) \cdot (y_i - \bar{y})}{N-1} \tag{6} \end{equation}\]Dieser Kennwert nennt sich Kovarianz (\(cov\)). Da dieser Kennwert an die entsprechenden Einheiten der Variablen gebunden ist, normiert man i.A. dieses Maß durch das Produkt der jeweiligen Standardabweichung \(s_x\) und \(s_y\). Dieses normierte Maß bezeichnet man als Korrelationskoeffizient (\(r\)):
\[\begin{equation} r(x,y) = \frac{cov(x,y)}{s_x \cdot s_y} \tag{7} \end{equation}\]Beispiel
Anhand des bereits verwendeten Datensatzes (CPS85) wollen wir die Beziehung der Variablen Gehalt (wage), Ausbildung (educ) und Berufserfahrung (exper) berechnen und graphisch darstellen. Kopiere den folgenden Code ins RStudio und führe diesen dann aus. Diskutiere die Ergebnisse.
M <- data.frame(wage = CPS85$wage, educ = CPS85$educ, exper = CPS85$exper)
Korr_1 <- cor(M)
pander(Korr_1, style = "rmarkdown")
# DT::datatable(round(Korr_1,2))
corrplot(cor(M), method = "ellipse")