Statistisches Modell
Ein statistisches Modell, manchmal auch statistischer Raum genannt, ist ein Begriff aus der mathematischen Statistik, dem Teilbereich der Statistik, der sich der Methoden der Stochastik und Wahrscheinlichkeitstheorie bedient. Unter statistischer Modellbildung versteht man dabei den Prozess, ein passendes Modell für die Daten einer Beobachtungsreihe zu finden.
- Als Prozess wird die strukturierte und gesteuerte Reihe von Arbeitsschritten bezeichnet, welche ein bestimmtes Ergebnis hervorbringen.
- Daten sind Werte und Beobachtungen, die im Lauf einer (statistischen) Erhebung gesammelt werden.
- Eine Erhebung ist die Sammlung von Daten einer bestimmten Grundgesamtheit zum Zweck der Untersuchung eines speziellen Aspektes. Die Daten werden oft nur von einer Stichprobe der Grundgesamtheit erhoben. Erhebungen sind in der Forschung weit verbreitet.
- Eine Stichprobe ist die Teilmenge einer Grundgesamtheit bei einer statistischen Untersuchung, zusammengestellt, um ausgewählte Eigenschaften der Gesamtpopulation zu untersuchen.
Modellbildung
Die Modellbildung abstrahiert mit dem Erstellen eines Modells von der Realität, weil diese meist zu komplex ist, um sie vollständig abzubilden. Man unterscheidet dabei:
Strukturelle Modellbildung: Bei struktureller Modellbildung ist die innere Struktur des Systems bekannt, es wird jedoch bewusst abstrahiert, modifiziert und reduziert. Man spricht hier von einem Whitebox-Modell.
Pragmatische Modellbildung: Bei pragmatischer Modellbildung ist die innere Struktur des Systems unbekannt, es lässt sich nur das Verhalten bzw. die Interaktion des Systems beobachten und modellieren. Die Hintergründe lassen sich meist nicht oder nur zum Teil verstehen - hier spricht man von einem Blackbox-Modell.
Mischformen: Bei Mischformen sind Teile des Systems bekannt, andere wiederum nicht. Nicht alle Wechselwirkungen und Interaktionen zwischen Teilkomponenten lassen sich nachvollziehen - hier spricht man vom Greybox-Modell. Diese Mischform ist die häufigste, weil es aufgrund von Kosten-Nutzen-Überlegungen meist ausreichend ist, das System auf diese Weise abzubilden.
Kennzeichen eines Modelles
Ein Modell ist im Wesentlichen durch drei Merkmale gekennzeichnet:
Abbildung: eines natürlichen oder eines künstlichen Originals, wobei dieses Original selbst auch wiederum ein Modell sein kann.
- Verkürzung: es erfasst im Allgemeinen nicht alle Eigenschaften (Attribute) des Originals, sondern nur diejenigen, die dem Modellschaffer bzw. Modellnutzer relevant erscheinen. Diese werden häufig in Form von aggregierenden Maßzahlen (Parameter) beschrieben.
- Pragmatismus: sind ihren Originalen nicht eindeutig zugeordnet. Sie erfüllen ihre Ersetzungsfunktion:
- für bestimmte Subjekte (für wen?)
- innerhalb bestimmter Zeitintervalle (wann?)
- unter Einschränkung auf bestimmte gedankliche oder tatsächliche Operationen (wozu?).
Im übertragenen Sinn ist damit ein statistisches Modell:
- Eine vereinfachte mathematisch-formalisierte Methode, sich der Realität anzunähern.
- Die Beschreiben des Zustandes eines Systems vor und nach Änderungen äußerer Relationen, nicht jedoch während einer Änderung.
Das Ziel ist es herauszufinden, ob man in der Natur auftretende Phänomene auf allgemein gültige Gesetzmäßigkeiten zurückführen kann. In der Regel werden Beobachtungen durchgeführt und diese als Daten aufgezeichnet. In diesen Daten gilt es Muster zu finden, die Rückschlüsse auf die Mechanismen zulassen, welche dem Phänomen zugrunde liegen. Auf diese Weise wird ein Modell von der Funktionsweise eines Phänomens erstellt.
Statistische Modelle finden Verwendung für:
- Annäherung (Approximation)
- Erklärung
- Vorhersage
Statistische Modelle sind in fast allen Anwendungsbereichen der Wissenschaft, aber auch des praktischen Lebens zu finden, wie z.B.:
- Bei Wettervorhersagen.
- In der Finanzmarktanalyse.
- In der Industrie und Gewerbe.
- Bei Wahlprognosen, Meinungsumfragen.
- In der Informationstechnologie.
- etc.
Zyklus der Modellbildung
Das Bilden von statistischen Modellen ist ein iterativer Vorgang, welcher durchaus mehrere zyklische Entwicklungsschritte beinhalten kann.
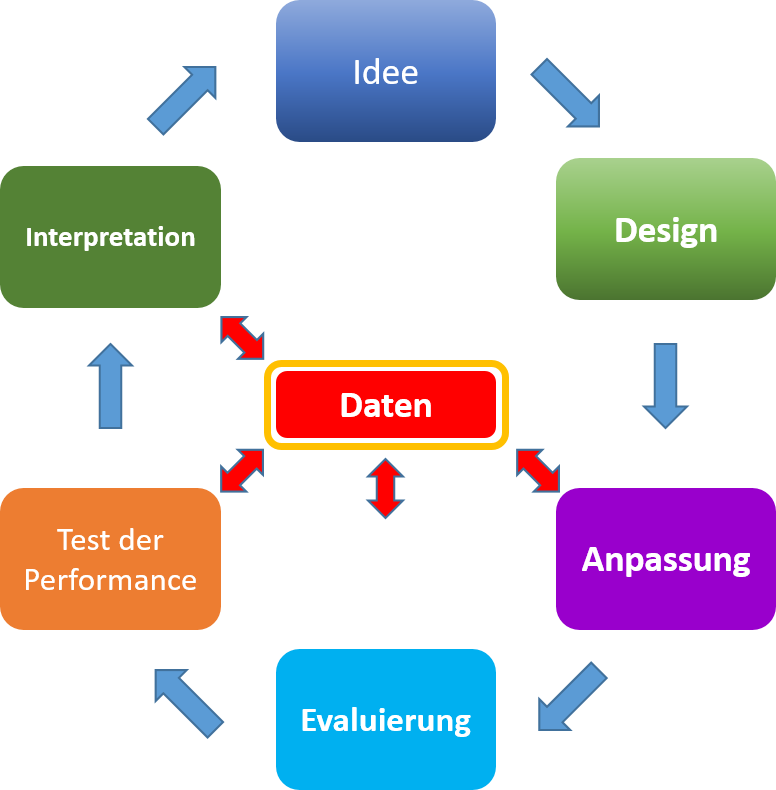
Abbildung 1: Zyklus der Modellbildung
Grundlagen der statistischen Modellbildung
Grundlage ist eine entsprechende Fragestellung, die auf theoretischen Grundlagen basiert und möglichst präzise formuliert werden soll. Bei den Daten, die zur Beantwortung der Fragestellung geeignet sind, sollte man speziell achten auf:
- woher Sie kommen.
- was und wie Sie ein erhobenes/gemessenes Objekt abbilden.
Charakteristiken von guten Fragen sind:
- Interessant für andere: wie z.B. für Mitarbeiter, wissenschaftliche Gemeinschaft, Geldgeber, Allgemeinheit?
- Noch nicht beantwortet: wurde die Fragestellung bereits bearbeitet/beantwortet? Das erfordert eine intensive Auseinandersetzung mit dem Thema (Literaturrecherche, Kongressbeiträge, etc.).
- Sinnvoll: kann durch die Beantwortung eine Erklärung gefunden werden, wie etwas funktioniert?
- Beantwortbarkeit: kann die Fragestellung überhaupt beantwortet werden?
- Spezifisch: wie präzise ist die Fragestellung? Gesundes Essen führt zu besserer Gesundheit ist weniger präzise wie z.B. 5 Mal am Tag Früchte und Gemüse führt zu einer geringeren Wahrscheinlichkeit an Atemwegserkrankungen zu erkranken.
Bei den Qualitätskriterien für Daten ist folgendes zu beachten:
- Korrektheit \(\rightarrow\) müssen mit der Realität übereinstimmen.
- Konsistenz \(\rightarrow\) dürfen in sich und zu anderen Datensätzen keine Widersprüche aufweisen.
- Zuverlässigkeit \(\rightarrow\) Entstehung der Daten muss nachvollziehbar sein.
- Vollständigkeit \(\rightarrow\) muss alle notwendigen Attribute enthalten.
- Genauigkeit \(\rightarrow\) müssen in der jeweils geforderten Exaktheit vorliegen (Beispiel: Nachkommastellen).
- Aktualität \(\rightarrow\) müssen jeweils dem aktuellen Zustand der abgebildeten Realität entsprechen.
- Relevanz \(\rightarrow\) Der Informationsgehalt muss den jeweiligen Informationsbedarf erfüllen.
- Einheitlichkeit \(\rightarrow\) Die Informationen müssen einheitlich strukturiert sein.
- Eindeutigkeit \(\rightarrow\) muss eindeutig interpretierbar sein.
- Verständlichkeit \(\rightarrow\) müssen in ihrer Begrifflichkeit und Struktur mit den Vorstellungen der Fachbereiche übereinstimmen.
- Redundanzfreiheit: Innerhalb der Datensätze sollen/dürfen keine Dubletten vorkommen.
Aus der Testtheorie sind in auch die Gütekriterien (Testgütekriterien) der empirischen Forschung für die statistische Modellbildung anzuwenden. Diese sind:
- Reliabilität: Indikator für die Replizierbarkeit der Ergebnisse. Fragen müssen z.B. so eindeutig formuliert sein, dass sie nicht höchst unterschiedlich verstanden werden können.
- Validität: wenn die gewählten Indikatoren, Fragen und Antwortmöglichkeiten wirklich und präzise das messen, was gemessen werden soll.
- Objektivität: wenn die Wahl der Messenden, InterviewerInnen, PrüferInnen keinen Einfluss auf die Ergebnisse hat.
Bei der Analyse und Interpretation der Daten unterscheidet man:
- Deskriptiv: beschreibend (innerhalb Daten)
- Explorativ: Hypothesen generierend (innerhalb Daten)
- Inferentiell: Statement über etwas, was nicht beobachtet wird, also aus den erhobenen Daten auf die Ursachen zu schliessen, die die Daten erzeugt haben könnten (außerhalb der Daten).
- Prädiktiv: Vorhersage für Werte die noch nicht beobachtet wurden (außerhalb der Daten)
- Korrelativ: Beschreibung der Zusammenhäng zwischen Beobachtungen (innerhalb und außerhalb der Daten).
- Mechanistisch: nicht nur die Frage ob ein Zusammenhang besteht, sondern wie und warum der Zusammenhang besteht ist von Interesse.
Deskriptive Statistik
Die deskriptive Statistik hat zum Ziel, empirische Daten durch Tabellen, Kennzahlen (auch: Maßzahlen oder Parameter) und Grafiken übersichtlich darzustellen und zu ordnen.
Die Methoden der deskriptiven Statistik umfassen:
- Tabellen
- Diagramme
- Parameter (Maßzahlen, Kennzahlen, Kennwerte)
- Lagemaßen: Maße der zentralen Tendenz, wie z.B. Mittelwerte, Median, Modus.
- Streuungsmaße: für die Variabilität (Dispersion), wie z.B. Range, Varianz, Standardabweichung, Standardfehler.
- Zusammenhangsmaße: wie z.B. die Korrelation.
Die deskriptive Statistik ist ein zentrales Element jeder formalen Analyse von Daten, hat jedoch in ihrer Eigenschaft folgende Einschränkungen:
- liefert keine Aussagen zu einer über die untersuchten Fälle hinausgehenden Grundgesamtheit .
- Es ist keine Überprüfung von Hypothesen möglich.
- Verwendet keine stochastischen Modelle (Grundlage der induktiven Statistik).
- getroffenen Aussagen können nicht durch Fehlerwahrscheinlichkeiten abgesichert werden.
Explorative Datenanalyse (EDA)
Die explorative Datenanalyse/Statistik hat zum Ziel, bisher unbekannte Strukturen und Zusammenhänge in den Daten zu finden und hierdurch neue Hypothesen zu generieren. Diese auf Stichprobendaten beruhenden Hypothesen können dann im Rahmen der schließenden Statistik mittels wahrscheinlichkeitstheoretischer Methoden auf ihre Allgemeingültigkeit untersucht werden.
Die Methoden der explorativen Statistik sind meist identisch mit denen der deskriptiven Statistik, unterscheiden sich aber bezüglich der Ziele der Analyse. Bei der EDA sollten vor allem die nachfolgenden Fragen geklärt werden:
- Haben wir die richtigen Daten zur Beantwortung der Fragestellung?
- Brauchen wir mehr Daten?
- Müssen wir die Fragestellung verfeinern?
- Was kann aus den vorliegenden Daten abgeleitet werden?
Die Ziele der EDA sind:
- bisher unbekannte Strukturen und Zusammenhänge in den Daten zu finden.
- Annahmen (Hypothesen) über die Ursache und den Grund der beobachteten Daten zu bilden.
- Annahmen einzuschätzen, worauf statistische Inferenz basieren kann.
- Die Auswahl von passenden statistischen Werkzeugen und Techniken zu unterstützen.
- Eine Basis für die weitere Datensammlung durch Umfragen oder Design von Experimenten bereitzustellen.
Speziell in Bezug auf die erforderliche Stichprobengröße sollte vor Begin der Datenerhebung die mindest notwendigen Fallzahlen (optimaler Stichprobenumfang) bestimmt werden, der für den Nachweise praktisch bedeutsamer Effekte notwendig ist. Sowohl in R als auch in diversen Anwednungen gibt es die Möglichkeit, diese optimale Stichprobengröße a priori zu bestimmen.
Voraussetzung dafür sind jedoch Kenntnisse über den zu erwartenden Effekt. Dieser kann entweder durch einer Meta-Analyse oder durch entsprechende Erfahrungswerte bestimmt werden. Zusätzlich ist dann noch die Irrtumswahrscheinlichkeit, die gewünschte Teststärke und die verwendete statistischen Methode festzulegen. Je größer eine Stichprobe ist, desto genauer werden auch die daraus abgeleiteten Kennwerte und Teststatistiken Auskunft über die in der Population gültigen Werte liefern. Aus praktischen/finanziellen/zeitlichen Gründen wird man jedoch i.A. danach trachten, eine möglichst kleine Stichprobe zu erheben. Generell lassen sich diesbezüglich folgende Aussagen treffen:
- bei großen Stichproben werden auch kleine Effekte im statistischen Sinn signifikant (damit ist nicht gesagt, dass auch eine praktische Signifikanz des Effektes vorliegt).
- bei kleinen Stichproben wird ein kleiner Effekt oft statistisch nicht signifikant. Wenn doch, ist das oft nur ein Zufallsergebnis und kann i.A. nicht reproduziert werden.
- eine sorgfältige Stichprobenplanung geht mit einer intensiven inhaltlichen Auseinandersetzung einher. Der Vorteil dieser Planung liegt also nicht nur in der Wahrscheinlichkeit, einen vorhandenen Effekt auch stastisch absichern zu können, sondern vor allem auch darin, dass eventuell schon beantwortete Fragen rechtzeitig entdeckt werden!
Inferenzstatistik
Bei der inferentiellen Statistik wird eine Zufallsstichprobe aus einer Grundgesamtheit entnommen, um Rückschlüsse auf die Grundgesamtheit zu ziehen und diese zu beschreiben. Weitere Begriffe sind:
- analytische Statistik
- inferenzielle Statistik
- induktive Statistik
- schließende Statistik
Die inferentielle Statistik ist in den Situationen nützlich, in denen es nur schwer oder gar nicht möglich ist, eine vollständige Grundgesamtheit zu untersuchen. Wesentliche Merkmale der Inferenzstatistik sind:
- trifft Wahrscheinlichkeitsaussagen über Populationswerte.
- Daten werden in Form von (Zufalls-) Stichproben aus der Grundgesamtheit entnommen.
- Signifikanztests und Intervalleschätzungen bieten die Entscheidungsgrundlage hinsichtlich der postulierten Hypothesen.
Prädiktive Statistik
Prädikative Statistik (predictive analytics) verwendet (historische) Daten, um zukünftige Ereignisse vorherzusagen. Im Allgemeinen werden vorliegende (historische) Daten verwendet, um ein mathematisches (prädiktives Modell) Modell zu erstellen. Dieses Modell soll bestmöglich wichtige Trends in den Daten erfassen.
Dieses wird dann auf aktuelle Daten angewendet, um zukünftige Ereignisse vorherzusagen, oder um Aktionen vorzuschlagen, mit denen optimale Ergebnisse erreicht werden können. Vor allem in den letzten Jahren hat diese Form der Statistik in den Bereichen von Big Data und Machine Learning sehr an Bedeutung gewonnen.
Mechanististische Statistik
Zusammenhängen zwischen mehreren Variablen mit gleichzeitiger Interpretation der Kausalitäten werden häufig mit Hilfe eines Strukturgleichungsmodells (SEM1) analysiert. Dabei handelt es sich um ein statistisches Modell, das das Schätzen und Testen korrelativer Zusammenhänge zwischen abhängigen Variablen und unabhängigen Variablen sowie den verborgenen Strukturen dazwischen erlaubt.
Eine Besonderheit von Strukturgleichungsmodellen ist das Überprüfen latenter (nicht direkt beobachtbarer) Variablen. Spezialfälle von Strukturgleichungsmodellen sind:
- Pfadanalyse
- Faktorenanalyse
- Regressionsanalyse
Ein Strukturgleichungsmodell stellt wiederum einen Spezialfall eines sogenannten Kausalmodells dar.
Structural Equation Modeling↩